缓存的设计
数据库的性能相比而言比较差,当用户量上来以后就不能直接读数据库,否则会导致连接数超过数据库连接串数,出现大量的慢请求,而且大量的数据其实并不会频繁的更新数据,这个时候就可以使用缓存来优化速度.比如使用redis,redis的读写速度要快于MongoDB,使用redis不仅可以减少MongoDB压力,也可以加快接口响应速度.
用户先请求redis,如果有数据就直接返回,不再查询数据库,如果redis中没有再查询数据库
缓存的读写策略
redis和MongoDB中都有一份数据,那如果两端的数据不一致怎么办呢?
Cache Aside 策略
如果先更新数据库后更新缓存,会出现什么问题呢?
在2个并发写请求时可能就会出现问题

因为变更数据库和变更缓存是两个独立的操作,而我们并没有对操作做任何的并发控制。那么当两个线程并发更新它们的时候,就会因为写入顺序的不同造成数据的不一致。
这个时候我们可以使用缓存最常见的策略,Cache Aside 策略(也叫旁路缓存策略),这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。
它可以分为读策略和写策略,其中读策略的步骤是:
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
- 更新数据库中的记录;
- 删除缓存记录。
但是Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。
如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快过期,对业务的影响也是可以接受。
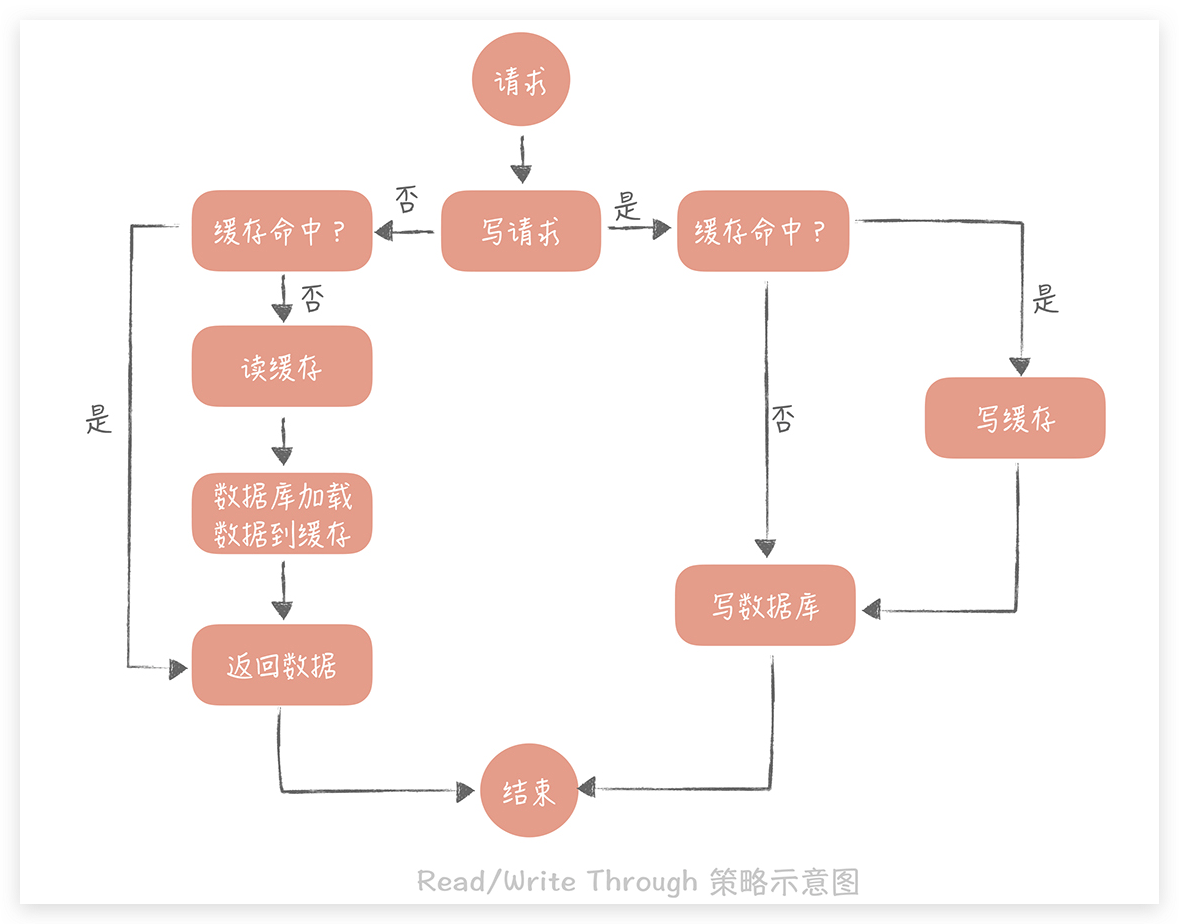
Read/Write Through(读穿 / 写穿)策略
这个策略的核心原则是用户只与缓存打交道,由缓存和数据库通信,写入或者读取数据。这就好比你在汇报工作的时候只对你的直接上级汇报,再由你的直接上级汇报给他的上级,你是不能越级汇报的。
Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做“Write Miss(写失效)”。
一般来说,我们可以选择两种“Write Miss”方式:一个是“Write Allocate(按写分配)”,做法是写入缓存相应位置,再由缓存组件同步更新到数据库中;另一个是“No-write allocate(不按写分配)”,做法是不写入缓存中,而是直接更新到数据库中。
这个策略需要有可靠性很强的组件去实现缓存到数据库同步这一步,可以将更新操作以命令的形式发送到消息队列中,让消费者去做数据库更新
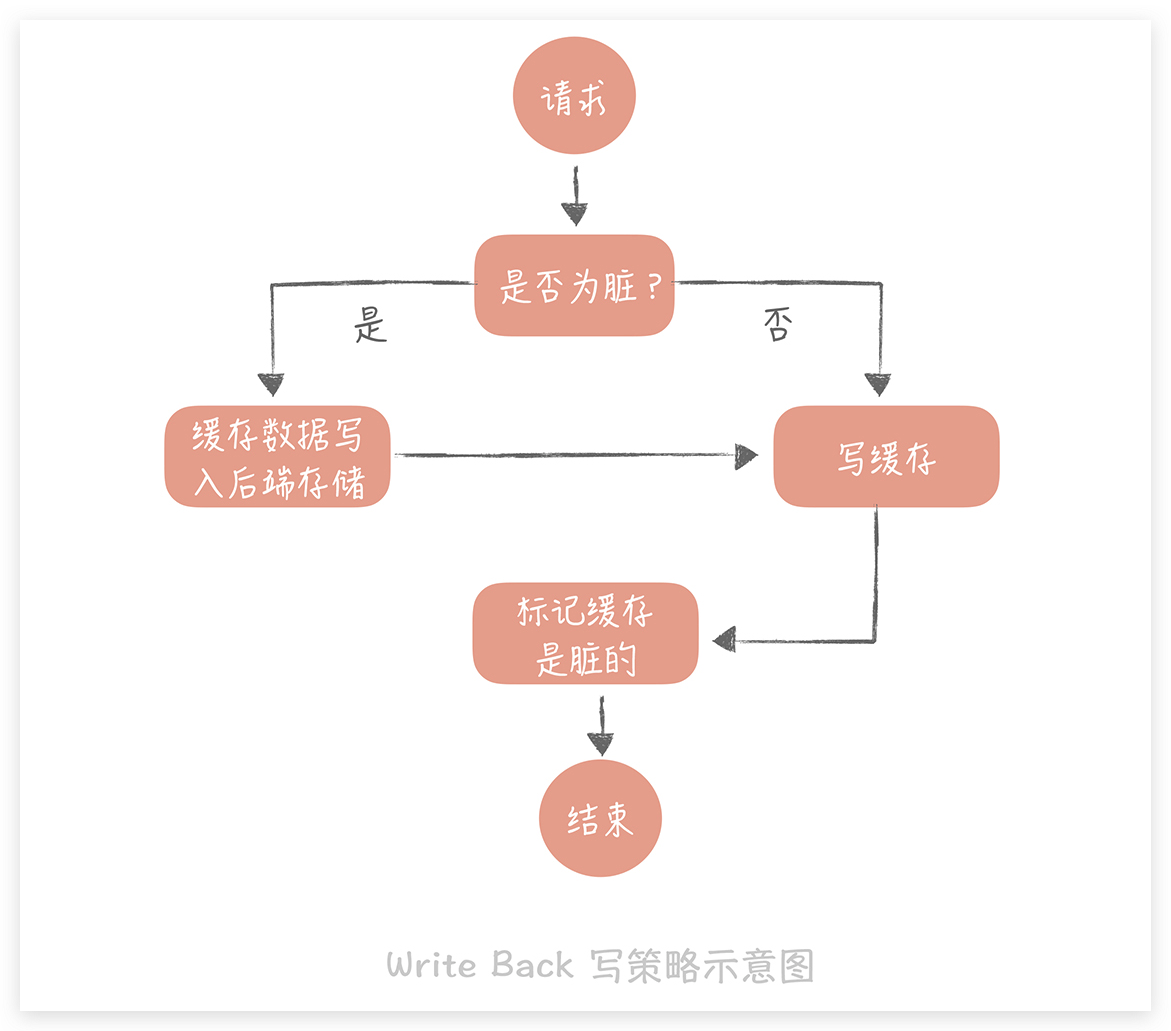
Write Back(写回)
策略这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块儿只有被再次使用时才会将其中的数据写入到后端存储中。不推荐使用.
缓存如何做到高可用
hash环
主从部署
缓存的穿透,雪崩,击穿以及如何处理
穿透
缓存穿透其实是指从缓存中没有查到数据,而不得不从后端系统(比如数据库)中查询的情况。
不过少量的缓存穿透不可避免,对系统也是没有损害的,主要有几点原因:
- 一方面,互联网系统通常会面临极大数据量的考验,而缓存系统在容量上是有限的,不可能存储系统所有的数据,那么在查询未缓存数据的时候就会发生缓存穿透。
- 另一方面,互联网系统的数据访问模型一般会遵从“80/20 原则”。“80/20 原则”又称为帕累托法则,是意大利经济学家帕累托提出的一个经济学的理论。简单来说,它是指在一组事物中,最重要的部分通常只占 20%,而其他的 80% 并没有那么重要。把它应用到数据访问的领域,就是我们会经常访问 20% 的热点数据,而另外的 80% 的数据则不会被经常访问。比如你买了很多衣服,很多书,但是其实经常穿的、经常看的可能也就是其中很小的一部分。
但是如果要读取一个用户表中未注册的用户,会发生什么情况呢?我们会先读缓存再穿透读数据库。由于用户并不存在,所以缓存和数据库中都没有查询到数据,因此也就不会向缓存中回种数据(也就是向缓存中设置值的意思),这样当再次请求这个用户数据的时候还是会再次穿透到数据库。在这种场景下缓存并不能有效地阻挡请求穿透到数据库上,它的作用就微乎其微了。那如何解决缓存穿透呢?一般来说我们会有两种解决方案:回种空值以及使用布隆过滤器。
回种空值
回顾上面提到的场景,你会发现最大的问题在于数据库中并不存在用户的数据,这就造成无论查询多少次数据库中永远都不会存在这个用户的数据,穿透永远都会发生。
类似的场景还有一些:比如由于代码的 bug 导致查询数据库的时候抛出了异常,这样可以认为从数据库查询出来的数据为空,同样不会回种缓存。
那么,当我们从数据库中查询到空值或者发生异常时,我们可以向缓存中回种一个空值。但是因为空值并不是准确的业务数据,并且会占用缓存的空间,所以我们会给这个空值加一个比较短的过期时间,让空值在短时间之内能够快速过期淘汰。这样空值存在的期间,就不会穿透到数据库层了.
回种空值虽然能够阻挡大量穿透的请求,但如果有大量获取未注册用户信息的请求,缓存内就会有有大量的空值缓存,也就会浪费缓存的存储空间,如果缓存空间被占满了,还会剔除掉一些已经被缓存的用户信息反而会造成缓存命中率的下降。所以这个方案,我建议你在使用的时候应该评估一下缓存容量是否能够支撑。如果需要大量的缓存节点来支持,那么就无法通过通过回种空值的方式来解决,这时你可以考虑使用布隆过滤器。
布隆过滤器
原理:我们把集合中的每一个值按照提供的 Hash 算法算出对应的 Hash 值,然后将 Hash 值对数组长度取模后得到需要计入数组的索引值,并且将数组这个位置的值从 0 改成 1。在判断一个元素是否存在于这个集合中时,你只需要将这个元素按照相同的算法计算出索引值,如果这个位置的值为 1 就认为这个元素在集合中,否则则认为不在集合中。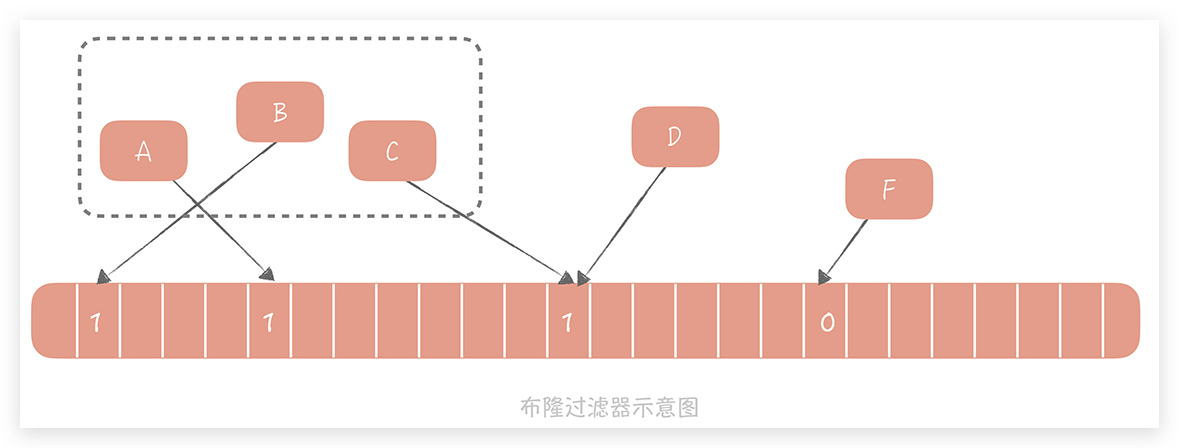
那么我们如何使用布隆过滤器来解决缓存穿透的问题呢?还是以存储用户信息的表为例进行讲解。首先我们初始化一个很大的数组,比方说长度为 20 亿的数组,接下来我们选择一个 Hash 算法,然后我们将目前现有的所有用户的 ID 计算出 Hash 值并且映射到这个大数组中,映射位置的值设置为 1,其它值设置为 0。
布隆过滤器拥有极高的性能,无论是写入操作还是读取操作,时间复杂度都是 O(1) 是常量值。在空间上,相对于其他数据结构它也有很大的优势,比如,20 亿的数组需要 2000000000/8/1024/1024 = 238M 的空间,而如果使用数组来存储,假设每个用户 ID 占用 4 个字节的空间,那么存储 20 亿用户需要 2000000000 * 4 / 1024 / 1024 = 7600M 的空间,是布隆过滤器的 32 倍。
布隆过滤器的误判有一个特点,就是它只会出现“false positive”的情况。这是什么意思呢?当布隆过滤器判断元素在集合中时,这个元素可能不在集合中。但是一旦布隆过滤器判断这个元素不在集合中时,它一定不在集合中。这一点非常适合解决缓存穿透的问题。
不过任何事物都有两面性,布隆过滤器也不例外
它主要有两个缺陷:
- 它在判断元素是否在集合中时是有一定错误几率的,比如它会把不是集合中的元素判断为处在集合中;这是由于hash算法的碰撞造成的.
- 不支持删除元素。
关于布隆过滤器的使用上,有几个建议:
- 选择多个 Hash 函数计算多个 Hash 值,这样可以减少误判的几率;
- 布隆过滤器会消耗一定的内存空间,所以在使用时需要评估你的业务场景下需要多大的内存,存储的成本是否可以接受。
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
解决方案:
- 设置热点数据永远不过期。
- 加互斥锁
使用这2个方案都有一定的风险,第一种方案会造成内存的使用量大大增加;第二种在回写缓存的期间其他用户都会无法获取数据,而且也要小心死锁的问题.所以如果不是必要性的数据,尽量不要使用这种方案.
缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
- 设置热点数据永远不过期。
缓存穿透总结
