JavaScript 中的定时任务
定时任务
一般在 node 中,执行定时任务的方式有:
- setTimeout
- schedule包
- 轮询 redis 或数据库
- 延时队列
setTimeout
setTimeout是最简单的办法.
1 | setTimeout(callback(), time); |
在 setTimeout 的第一个参数里传方法或者需要执行的语句, 第二个函数传毫秒数,当 setTimeout 被执行后,就开始到技术 time,时间到了以后就会执行第一个参数.
在这里要注意的是,如果传的不是方法而是语句则需要加上引号变成字符串参数.因为 setTimeout 方法是使用了eval函数,但是出于对 eval 函数的安全顾虑,以及 js 的性能考虑,还是尽量不要直接传 js 语句,而是使用匿名箭头函数
1 | setTimeout(() => { |
这样就是执行方法,而且还避免了另一个 setTimeout 方法容易出错的地方
setTimeout中的this关键字将指向全局环境
如果setTimeout 第一个参数传入正常的函数
1 | const x = 1; |
输出的是1而不是2,这是因为 setTimeout 是全局对象window 的一个方法,所以在 setTimeout中的 this 指向的是全局环境.所以应该尽量在 setTimeout 中传入箭头函数, 箭头函数会绑定当前 this.
schedule 定时任务
node-schedule 是一个定时任务包,设定好时间以后,传入的方法就会在预定的时间执行.并且是循环执行.
1 | const schedule = require('node-schedule'); |
以上代码就是在每分钟的30s 都执行 function(),这里的第一个参数是 cron 风格的时间设定
corn风格定时器
1 | * * * * * * * |
corn 风格的时间设定是由7位数组成,每个位置的符号或者数字表示不同的意思,
*代表不指定,可任意时间都满足
比如30 30 * * * ? 就代表的是每小时的30分30秒,30 30 13 * * ? 代表每天的13点30分30秒,30 30 13 1 * ? 代表每个月1号的13点30分30秒,30 30 13 1 5 ? 代表每年的5月1号13点30分30秒,
最后的?指定星期几的,如果指定了具体几号,那么星期几就没有指定,两者很多时候是冲突的,所以就用?代表随意星期几都可以.而最后一位的年很少会用到,毕竟指定某一年的定时任务需求非常少.
参考: corn 表达式生成网站
轮询 redis 或数据库
众所周知的 redis 有设置过期时间的功能, 在 redis 中设置一个独特的 key-value,然后设置它的过期时间,然后在代码里设置轮询,当查不到这个 key 的时候就执行函数.
1 | while(1) { |
这种方法虽然也能做到定时任务,并且非常简单,但是长时间的 io 操作,非常影响效率.所以不推荐使用
mq 延时队列
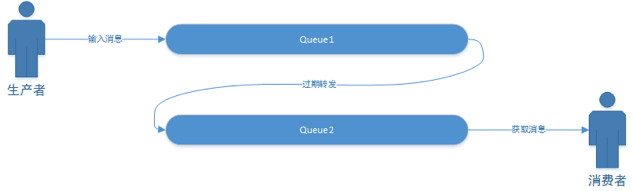
rabbit 延时队列流程:
创建普通交换器->创建正常队列->绑定普通交换器和死信交换器、死信路由->发送消息,设置过期时间->TTL 过期-> 被发送到死信交换器->消费者创建死信交换器-> 消费者创建死信队列-> 绑定死信队列到死信交换器上->死信交换器把 msg 发到死信队列上->消费者拿到数据
rabbit npm amqplib包的实现
1 | client.sendDelayedMessage = async (content, queueName, expires) => { |
总结:
优点: 高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
缺点: 本身的易用度要依赖于rabbitMq的运维.因为要引用rabbitMq,所以复杂度和成本变高.